2023 年 12 月,北京互联网法院公开开庭审理了在大模型时代下,国内已知的 AI 绘画第一案。
案件是这样的:有人在网上看到一张 AI 生成的女神图,很美很动人,琢磨着毕竟是 AI 生成的,不会跑来要版权,就直接转发到自己的自媒体平台。
AI 确实没办法跑来要版权,但控制 AI 生成这张女神图的人来了,法院的宣判也来了——北京互联网法院从司法层面对“ AI 绘画是否构成著作权法意义上的作品”作出认定,认定了原告拥有AI 绘画作品的著作权,并判处被告赔偿人民币500元。

援引案例中图片有可能会存在版权风险,所以我们通过midjourney工具,进行了AI重制。
这个判决的金额虽小,但本案的特殊之处在于这张绘图作品系通过“稳定扩散模型”(stable diffusion model)在电脑中生成,也就是说它不是原告的画作,而是一幅基于人类给出的“提示词”,由 AI 程序自动生成的作品。
这个判决一出,立即引起了法学界和人工智能产业圈的讨论,众多相关人士和学者以不同的形式,对该判决提出了自己的不同意见。
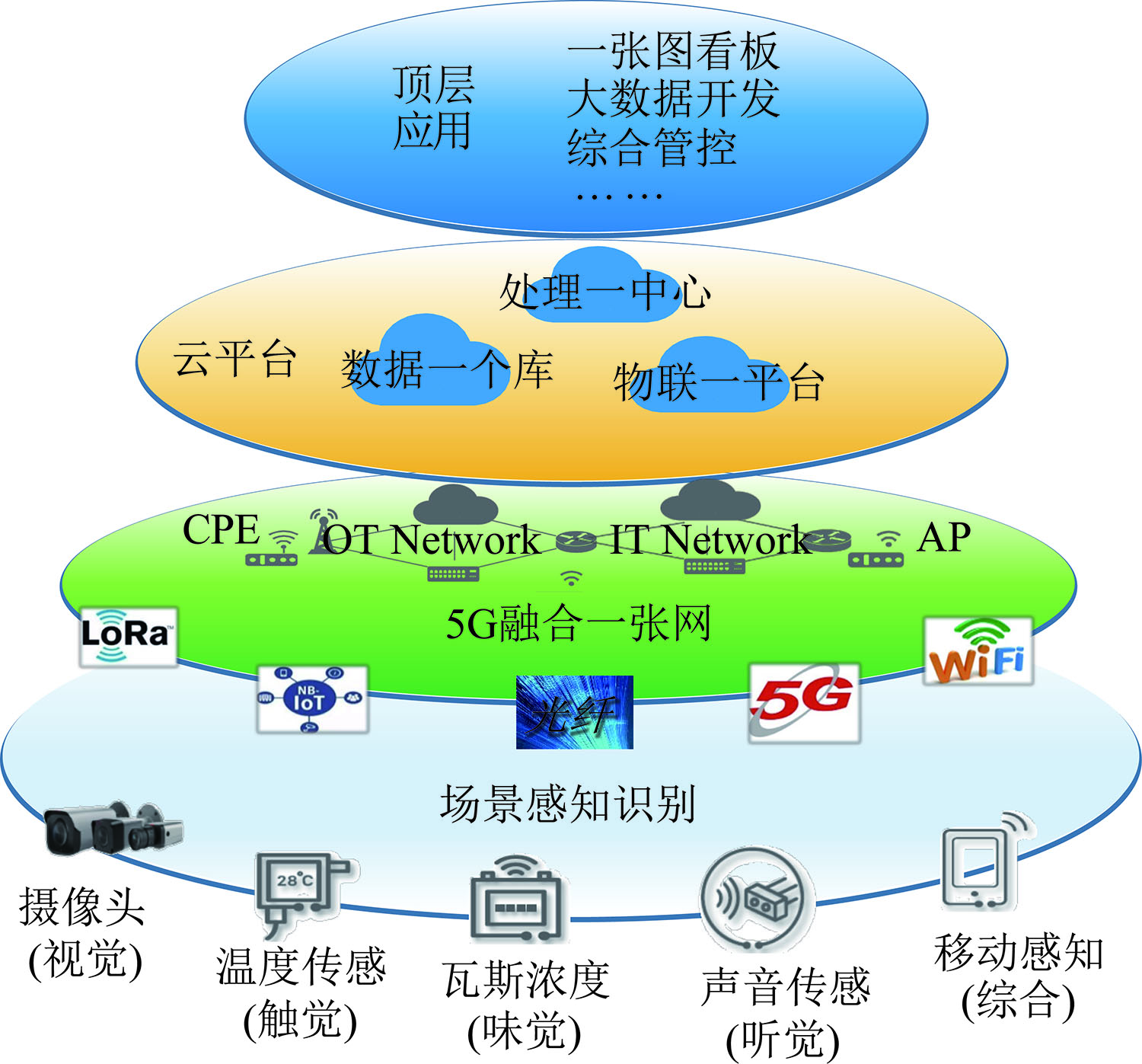
什么是“稳定扩散模型”?
“稳定扩散模型”发布于 2022 年,是一种深度学习人工智能模型。经过训练,它可以逐步对随机高斯噪声进行去噪操作,以获得图像样本。
该模型主要用于根据文本产生图像,尽管它也可以应用于其他任务,如图像修复、图像扩展,以及在提示词的指导下进行图生图或者文生图。
就技术路线而言,稳定扩散是一种扩散模型(diffusion model)的变体,是“潜在扩散模型”(latent diffusion model)的进一步发展。

图片由 AI 生成,来自平台 midjouney
稳定扩散模型由互联网上大量图片和其对应文字描述训练而来,该模型可以根据文本指令,利用文本中包含的语义信息与图片中包含的像素之间的对应关系,生成与文本信息匹配的图片。该生成的新图片不是通过搜索引擎调用已有的现成图片,也不是将软件设计者预设的各种要素进行排列组合。
通俗来讲,该模型的作用或者功能类似于人类通过学习、积累具备了一些能力和技能,它可以根据人类输入的文字描述生成相应图片,代替人类画出线条、涂上颜色,将人类的文字创意、构思进行有形呈现。
不同于其他基于云端的 AI 服务,经过预训练的稳定扩散模型是开源的,源代码可以公开下载,并安装在本地计算机中运行。因而这种工具已经广泛运用于商用图片的生产中。
AI 创作的图片,为什么著作权归人?
2023 年 12 月,北京互联网法院作出的(2023)京 0491 民初 11279 号判决,认定 AI 绘图作品的著作权归属于原告。
做出以上判决的理由是:
原告发布涉案图片时已经标注为“AI 插画”,且原告可以利用稳定扩散模型根据自已设定的提示词和参数还原该图片的生成过程。
当然,无法还原生产具体这张诉争图片的过程,因为该图片的生成本身具有随机性。在无相反证据的情况下,可以认定涉案“春风送来了温柔”图片系原告利用生成式人工智能技术生成的。
法院认为从构思涉案图片起,到最终选定涉案图片止,这整个过程来看,原告进行了一定的智力投入,比如设计人物的呈现方式、选择提示词、安排提示词的顺序、设置相关的参数、选定哪个图片符合预期等等。涉案图片体现了原告的智力投入,故涉案图片具备了“智力成果”要件。
根据法院评述,本案中原告指令稳定扩散模型按照其输入的提示词创作类似“委托他人创作”。如果稳定扩散模型是一个具体的人类,那么本案原告显然不是绘图作品的作者。
但是稳定扩散模型不是人类,也不是法人,不是著作权法条上的主体,因此不能享有著作权,著作权就归“告诉 AI 应该怎么画”的原告李某。
与本案类似的,深圳南山法院在 2018 年 10 月一个判决里显示:“涉案文章由原告主创团队人员运用腾讯写作机器人(Dreamwriter)生成,其外在表现符合文字作品的形式要求,其表现的内容体现出对当日上午相关股市信息、数据的选择、分析、判断,文章结构合理、表达逻辑清晰,具有一定的独创性”。
法院认定,由腾讯写作机器人在技术上“生成”的创作过程满足著作权法对文字作品的保护条件,属于我国著作权法所保护的文字作品,因此判定被告赔偿原告经济损失及合理的维权费用人民币 1500 元。
到底什么是著作权?
法律层面的作品著作权包括了发表、署名、修改等人身性权利,以及复制、出租、表演、改编等财产性权利。财产权可以许可他人行使,也可以全部或者部分转让给他人,但人身权属于作者是不能转让、授权的。
也就是说如果一幅作品被判定著作权属于某个权利人,在没有相反约定的前提下,他就有权禁止他人复制该作品,也有权禁止将该作品用于其他 AI 模型的训练。
《中华人民共和国著作权法》对于“作品”的定义为——指文学、艺术和科学领域内具有独创性并能以一定形式表现的智力成果。公民、法人或者非法人组织的作品,不论是否发表,依照本法享有著作权。
美国《1976年著作权法》(Copyright Act of 1976)中受保护的作品必须是“用现有的或将来制造出来的任何物质表现形式固定下来。直接或借助于机械装置,能被人们觉察到、复制或用其他方法传播的原作”,主要有文字作品、音乐作品、戏剧作品、哑剧作品和舞蹈作品、图片绘画作品及雕塑作品、电影作品与其他视听作品、录音制品、建筑作品。口头作品未经固定,不受保护。著作权的保护范围仅限于作品的表现形式,而不扩及其思想 。
本质上,著作权保护的是人类的表达,即人和人类组成的组织(法人)都可以成为一个作品的“作者”,这两者之外的动物、植物或其他非生物体不能成为著作权法上的“作者”。
一个将颜料随机泼洒在画布上画家,可以拥有该后现代艺术风格作品的著作权,因为整个创作过程虽然是随机、不可重复的,但是是由“人类”完成了“绘画”这一表达过程。但一个故意将调好了快门、光圈参数的相机扔给猴子的摄影师,不能声称拥有猴子拍摄照片的著作权,因为他只是为创作提供了范围和条件,但并没有完成摄影创作本身。
同样的思想实验中,一个将画笔和颜料递给大象的驯兽员,也不能主张拥有大象绘制“作品”的著作权,尽管他的确“训练”该大象绘画,但他无法控制大象绘画的最终过程和表达结果。
不要以为这是夸张的说法,“猴子拍照片”是有真实案例的。
2001年,英国户外摄影师斯莱特(David J. Slater)在印尼北苏拉维西国家公园参观时偶然得到了一张黑冠猕猴的“自拍照”。
该照片随即被全球多家媒体疯转,并掀起了维基百科与斯莱特之间的著作权大战。
斯莱特声称自己拥有这张照片的著作权,维基百科提供该图片的公开下载使其损失巨额版税收入,但维基百科方面表示任何人都不拥有该照片的著作权,因为这张照片是猴子拍的。
2014 年 12 月,美国版权局(USCO)声明,非人类所创作的作品不被美国著作权法保护。

猕猴的自拍照,图源:MediaWiki
对于本文讨论的 AI 生成图片著作权问题,美国联邦地区法官贝利尔·豪威尔(Beryl A. Howell)在2023年8月18日驳回了 AI 企业家史蒂芬·泰勒(Stephen Thaler)对美国版权局的诉讼,她裁定由AI生成的艺术作品不受著作权保护,并强调人类创作是“有效著作权主张的重要组成部分”。
与北京互联网法院相反的是,在本案中虽然原告也“提供指令并指挥其人工智能创造作品”“人工智能完全由(他)控制人工智能只在(他)的指示下运行”,但是美国法院依然认定“作者为人是著作权的基本要求”。

美国法院判决照片,图源:MediaWiki
笔者认为,不同法院判决不同的原因在于对著作权完成创作的主体是否必须为“人”的价值判断不同,以及对于稳定扩散模型这种 AI 工具真正的内在原理理解不同。
在一些判例的逻辑中,Diffusion model 就相当于人类手中的铁锤或者画笔,背后在控制工具的依然是操作工具的具体人类。
但在另一些判例的逻辑中,人类使用 AI 工具就像将画笔扔给了大象或者拿到了相机的猴子,虽然人类发出了各种“指令”,但“创作”这个过程并不是人类完成的。
人工智能学习模型潜在的作品版权问题
稳定扩散模型这样的人工智能模型需要大量的原始数据或图片用于训练,这些案件中的原告输出的图片均是数量巨大的原始图片用于训练的结果。
2023 年 4 月 11 日,国家互联网信息办公室发布《生成式人工智能服务管理办法(征求意见稿)》,提出深层次人工智能产品或服务,应当尊重知识产权商业道德,对隐私、知识产权、训练数据、不公平竞争等设立了“藩篱”,特别明确了用于生成式人工智能产品的预训练、优化训练数据不得侵权。
就在几个月前,2023 年 1 月,全球最大图片分销商之一盖帝图像(Getty Image)起诉稳定扩散模型的创作者团队,指控后者在无授权的情况下滥用其数百万张版权图片当作训练数据——因为该模型生成的图片中出现了扭曲但依然清晰可辨的盖帝图像的水印(这种水印会出现在非授权图片的预览上)。
但机器学习模型是建立在贝叶斯运算基础上的,其本身的数学原理决定过程的黑箱性和不可解释性,人类无法观察最终图像生成的具体步骤。除非发生了上述的这种“意外”,我们也无法判断生成的图片是基于具体的哪些数据迭代而成的,更遑论这些数据是否得到了合法的授权。
就好比我现在无法描述写下现在的这篇文字的语言片段和知识来自我人生中具体哪一次的阅读——那么,我用于这篇文章写作的数据集的作者们——那些小学教科书的作者们,能否向我主张这篇文章的改编权授权?以及让我们更进一步,如果我有意无意读过盗版书,那书的原作者又应当如何向我主张他应得的权利呢?
更深远的未来
当新的生产力和生产工具出现的时候,需要改变的往往是人们的认知和规则。
当前深度学习模型算法都是处在封闭的环境中,训练程序员提供的数据集和遇到的实际数据,在封闭环境的模型分布是不变的。而实际人类生活中,我们所处的环境是开放和随机的,无法穷尽所有数据和可能,这也是计算机和程序的表达可能与人类表达本质上的不同。
法律本身只是抽象的人类共识,就 AI 作品能否获得著作权的问题,我们已经看到了不同的判决。一些法官对于能否认定 AI 作品的著作权问题上明显更为保守。
对于人类用“参数”和“条件限制”而制造的作品是否应当赋予著作权利,这些图片的作者到底是程序本身,还是那个只是输入了几个提示词的人类,恐怕并不是一个容易回答,且有着固定答案的问题。
毕竟,代码在以人类看不到的方式快速迭代,算力在飞驰电掣的提升,作者和作品的标准在学术界仍然存在着巨大争议。
我们相信在可以预见的未来中,这些争议本身也可能成为人类技术继续前进的注脚和动力。
策划制作
作者丨蒋一凡 北京市康达(深圳)律师事务所 律师
审核|赵虎 北京市中闻律师事务所 律师
策划丨徐来
责编丨林林