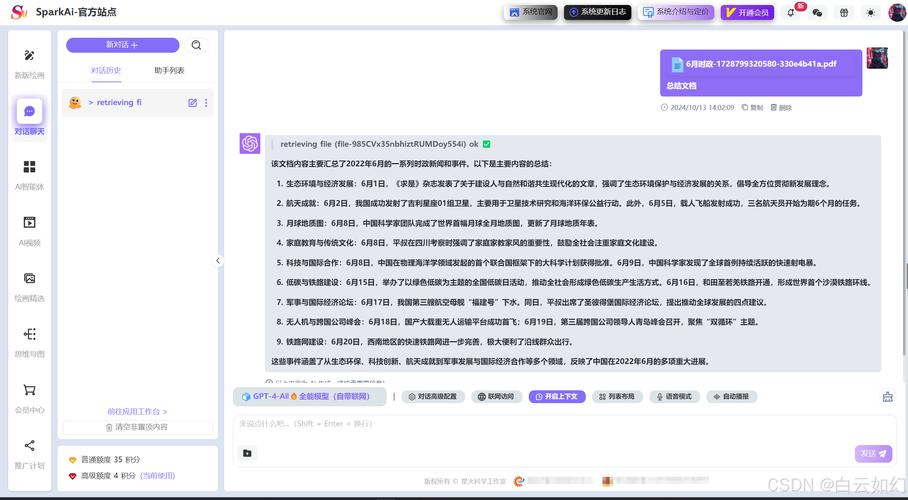
12月19日,智源研究院发布的大模型评估数据受到了广泛关注。在这些数据中,众多国产模型的表现格外引人注目,其排名情况成为显著特点。这些结果不仅反映了模型技术的进展,还与科技产业的竞争态势密切相关。
评测总体概况

智源研究院近期发布的评测内容覆盖了国内外超过100个开源和商业闭源的大规模模型。这一评测活动意义重大,目的是对当前大模型的发展进行全面评估。广泛的评测有助于揭示各模型的真实性能,为行业发展趋势提供指引。FlagEval评测平台,由全国多所高校和机构共同建设,体现了社会各界对大模型研究和评估的高度重视。资源的有效整合,有助于产生更为客观和精确的评估结果。


豆包在大语言模型主观评测表现

豆包通用模型pro在主观评测中,特别是在针对大语言模型的中文处理能力评测中,成绩优异。评测结果显示,该模型在知识应用和推理方面得分最高,同时在简单理解、数学和安全等多个领域均名列前茅。这一成就归功于其背后强大的算法和数据支持。然而,在FlagEval大模型竞赛中,豆包通用模型pro虽以用户对战投票的形式获得第二高分,仅次于OpenAI的o1 - mini,这也反映出不同评测方法和用户认知可能存在的差异。
多模态模型评测情况

评测数据表明,多模态模型领域的排名同样引起了广泛关注。在视觉语言模型这一细分领域,GPT-4o占据榜首位置,豆包视觉理解模型紧随其后,排名第二。尽管豆包视觉理解模型未能获得冠军,但它的表现依然值得肯定。尤其在中文通用知识和文字识别领域,豆包相较于国际同类模型具有明显优势。这一成就体现了豆包在本地化服务及中文相关视觉理解任务上的独特优势。评测主要针对图文理解等多重能力,豆包在这些领域的卓越表现,充分证明了其不断积累和进步的能力。
文生图与文生视频测试

文生图及文生视频测试领域竞争激烈,众多模型参与角逐。在文生图测试中,混元和豆包表现优异,排名靠前。在文生视频测试方面,国内模型展现出明显优势,可灵1.5高品质版、即梦P2.0 pro、爱诗科技PixVerse v3和海螺AI等均位于前列。这些成果充分体现了国产模型在新兴领域的崛起势头,它们在技术研发和算法优化上的投入取得了积极成效,同时也表明国产模型在满足本土市场需求方面拥有独特的创新能力。

豆包视觉理解模型开放使用

豆包视觉理解模型最近在火山引擎Force大会上展出,并已向企业用户推出。这一事件标志着豆包模型商业化的重大突破。火山引擎指出,豆包大模型通过技术创新大幅减少了使用成本,降低了企业使用的难度。豆包模型开放使用的主要目的是推动AI技术的广泛应用,众多企业对此抱有期待,希望它能助力企业实现业务创新。

大模型评测的影响与展望

此次评测对于企业来说,其结果能作为技术改进和研发策略调整的依据。用户可以通过这些结果来选择更符合需求的大模型产品。从长远看,随着技术发展,评测范围将进一步拓宽,覆盖更多模型和更复杂的项目。同时,模型间的竞争也将变得更加激烈。以豆包为例,它需要考虑如何提升自身实力,缩小与领先模型的差距,并保持现有优势。我国的大模型有望逐步实现国际领先,这一点备受期待。对于国产模型,如何有效运用评测成果,加强技术研发,提升国际竞争力,将是一个重要挑战。

各位读者,探讨国产模型在市场竞争的未来,请问您认为其核心优势领域为何?热切期待您的宝贵意见、点赞以及文章转发。