近期,科技领域传来重大新闻。OpenAI公布的报告揭示,GPT-4o和4o-mini模型遭遇性能下滑挑战。这一现象如同湖面投石,引发了广泛的关注。与此同时,科研团队新推出的LONGPROC基准测试工具也成为了热议的焦点。
OpenAI模型性能下降

1月20日,快科技报道,OpenAI宣布GPT-4o及4o-mini模型的性能有所降低。目前,对此展开的调查活动仍在进行中。公众对后续进展充满期待。这一变化可能对依赖这些模型的软件产生负面影响。对于采用GPT-4o开展业务的企业,有必要重新审视其运营策略。同时,普通用户在使用相关服务时,可能遭遇错误回复等问题。
性能的降低可能与算法和数据的多个层面有关。鉴于OpenAI模型应用领域的广泛性,此次性能的降低可能产生的影响,或许超出了之前的预期评估。

LONGPROC基准测试工具诞生
近期,科研团队开发了一款名为LONGPROC的基准测试工具。该工具专注于评估模型在处理长文本和生成对应回复时的信息处理复杂性。LONGPROC的问世,为模型性能的评估引入了新的评价标准。

信息技术发展迅猛,对于一款专注于提升长文本处理性能的检测软件而言,其重要性愈发凸显。过去,此类软件在准确评估模型的长文本处理能力方面存在不足。新工具的问世或许将推动模型开发者对模型设计进行深入反思。同时,该工具的运用也可能催生科技领域的创新研究活动。
实验中的意外结果

实验数据揭示,GPT-4o等众多顶尖模型在常规长文本记忆测试中表现尚可。然而,当面对复杂的长文本生成任务时,这些模型暴露出诸多缺陷。这一观察结果表明,尽管现有模型具备一定能力,但在处理复杂任务方面,它们还需继续提升。
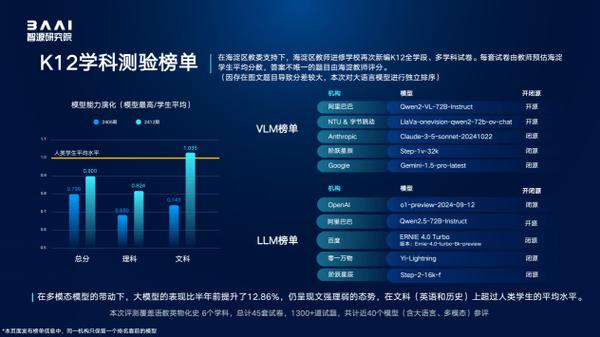
众多大型模型声称具备高效处理大范围上下文的能力,但实际表现与宣传描述存在较大差距。具体来看,开源模型在处理2K个token的任务时已显力不从心,即便是GPT-4o等闭源模型,在8K个token的任务中,其性能也明显下滑。这一现象表明,模型性能可能被过分夸大,同时也提示我们对模型能力的认识尚存诸多盲点,亟需进一步探索和研究。
GPT - 4o的幻觉现象

以GPT-4o为例,即便输入了精确信息,在构建旅行行程时仍有可能出现错误的航班信息。这种现象被称为“幻觉”。在具体应用过程中,这一问题尤为显著。它不仅可能对用户的使用体验造成影响,还可能使用户做出不正确的决策。

该现象揭示了模型在信息整合上可能存在偏差,亦或是其推论能力尚需增强。这一问题亟待解决,尤其是考虑到模型已广泛应用的现状。同时,这也促使人们对于人工智能模型数据真实性及处理逻辑进行了更深入的反思。
模型在长内容生成的不足

研究数据表明,即便是最先进的模型,在产出连贯且篇幅较长的内容时,仍有改进的可能。尤其在处理8k token输出任务时,即便是参数丰富的模型,其表现往往不尽理想。这一发现为大型语言模型(LLM)的研究领域开辟了新的、具有潜力的研究方向。
企业若欲提升模型性能,必须加大资源投入。教育机构及科研单位应深化对此问题的研究,有望在该领域实现突破,进而推动整个行业技术水平提升。
对未来模型发展的预示


该研究为大型语言模型的发展提供了新的观察角度。研究指出,单纯提升模型的特定参数并不能保证获得预期效果。开发者需关注模型在处理长文本等复杂任务时的实际性能。此外,研究还表明,在增强模型处理长文本的能力上,存在广阔的研究领域等待深入探索。

科研人员将其视为一块尚未充分开发的宝贵资源。研究进展显示,该模型在处理长文本及减少错误率的能力上,预期将有显著进步。这一进步将提升人工智能的信赖度和可靠性,进而更有效地服务于人类社会。

您期望模型在哪些性能维度上得到改善?我们热切期待您的宝贵反馈。此外,我们也诚挚邀请您对本文给予点赞及推广。