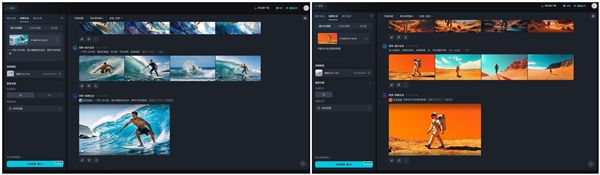
12月17日,谷歌推出了全新的AI视频生成模型Veo 2。这一发布在科技界引起了显著的关注,被视为一个重要的里程碑。同时,它也激发了广泛的讨论和热议。
Veo 2的基本参数

Veo 2模型功能强大。该模型可生成分辨率高达4K(4096 x 2160像素)的视频,且视频时长最长可达2分钟。与OpenAI的Sora模型相比,Veo 2的分辨率提升了4倍,时长增加了6倍。这些数据充分显示了Veo 2在视频生成领域的卓越表现。凭借这一能力,制作高清视频内容或满足特定商业视频需求变得更加容易实现。


12月17日是一个值得关注的日子,这一天谷歌发布了一项新举措,这或许标志着该公司在人工智能视频生成领域的战略调整。
Veo 2的功能特性

Veo 2具备根据文本提示或结合参考图像生成视频的能力。同时,它能更逼真地再现运动、流体动力学和光线特性。通过推特上网友分享的切西红柿对比视频,我们可以明显看出,Veo 2在这些方面明显优于其他模型。这些特性使得Veo 2在视频制作领域具有广泛的应用前景。
Veo 2适用于多种视频创作场合。例如,在创意广告制作中,它能依据创作者的文案内容,精确生成带有特殊光影和动态效果的视频内容。
与Sora的对比优势

Veo 2相较于Sora模型展现出明显优势。其分辨率与时长数据充分体现了其先进性。此外,在功能上,Veo 2亦明显超越Sora模型。比如在运动、流体动力学以及光线模拟等方面,Sora模型显得不足。因此,Veo 2在实际应用中更能满足用户对高质量视频的期待。

当前视频制作领域竞争愈发激烈,Veo 2凭借其独特优势,有望快速抢占市场份额,并吸引众多内容制作者转而采用Veo 2进行创作。
Veo 2的增强之处

Veo 2在保真度上实现了细节的显著提升,增强了画面真实感,并有效降低了伪影。它在准确度方面表现出对物理世界的深刻理解,能够精确遵循详细指令,对运动的表现达到高度准确。在相机控制能力上,Veo 2掌握了电影摄影的专业语言,能够实现多种拍摄风格、角度和动作的创建。这些方面的改进共同提升了视频的整体质量和表现力。
在制作纪录片的过程中,该技术能够精确地针对内容需求,模拟出拍摄所需的多个视角和动作。
防范Deepfake风险
为了减少Deepfake带来的风险,谷歌的DeepMind采用了专有水印技术SynthID,将不易察觉的标识嵌入至Veo 2生成的视频帧中。这一做法旨在保障视频内容的可追踪性和真实性。鉴于AI视频生成技术可能被用于散布虚假信息,此举措显得尤为迫切且富有远见。

此措施将鼓励众多用户勇于运用Veo 2制作视频,无需担忧遭受恶意利用的风险。
Imagen3绘图模型

Veo 2之外,谷歌新发布了升级版的AI绘图工具Imagen 3。该模型在生成图像的细节上有所提升,光线效果更加丰富,且减少了干扰。这一进展对绘图界而言是个积极信号,无论是职业艺术家还是业余爱好者,都有望从中获得益处。


Imagen3能否像Veo 2那样在市场上引发新一波热潮?期待大家在评论区发表见解。同时,诚挚邀请各位点赞并转发本篇文章,以便让更多人认识谷歌的最新研究成果。