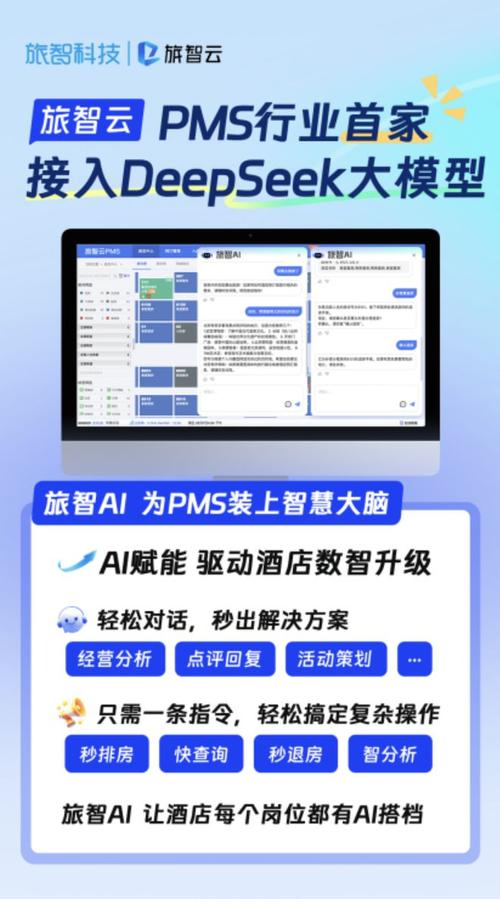
算法问世:华为创新突破

1月24日,华为AI算法团队实现了重要突破,成功研发并发布了新型大模型压缩算法——KV Cache RazorAttention。在人工智能领域竞争激烈的当下,这一成就犹如平静湖面的一颗巨石,迅速引发了业界的极大关注。该团队专注于研究,努力解决大模型推理难题,为行业的发展做出了积极贡献。

华为在人工智能技术方面拥有稳固的底蕴。其AI研究团队持续深入探索,研究领域广泛,包括基础理论研究至实际应用等多个层面,不断追求创新。这一算法的成功推出,正是团队不懈努力的直接体现。
性能卓越:节省内存显著

RazorAttention算法表现出色,有效减少了大型模型推理过程中的内存需求。其效果显著,最高可节省70%的内存。在AI大型模型的运行中,内存资源至关重要。内存使用过高不仅会降低运行效率,还会增加成本。该算法如同精准的手术刀,精确地解决了内存占用问题。
过去,大型模型在长序列的KV Cache压缩方面表现不佳。然而,RazorAttention算法通过技术创新,成功解决了这一挑战。在具体测试中,该算法实现了误差率低于1%的高精度,同时大幅减少了KV Cache的内存占用,为大型模型的高效运行打下了坚实的基础。
论文收录:获国际认可

华为提交的论文《RazorAttention:通过检索头实现高效的KV缓存压缩》荣获了深度学习领域顶级会议ICLR 2025的认可。ICLR在深度学习领域内享有盛誉,被视为衡量该领域科研水平的标杆。

论文收录证实了RazorAttention算法的创新性与领先地位。华为的研究成果赢得了国际同行的广泛赞誉。这一成就预计将吸引更多关注,并促进学术交流与技术创新合作的深入。此举显著提升了华为在人工智能领域的国际声誉,同时也为全球人工智能研究注入了新的活力。
业界首创:基于可解释性

华为指出,RazorAttention技术是行业内首个实现Attention机制可解释性的离线静态KV Cache压缩技术。尽管Attention机制在人工智能领域应用广泛,但其可解释性一直面临难题。华为此次创新性地关注可解释性,为算法设计提供了新的思路。
该设计强调信息的可理解性,从而提升了算法的学术价值和信任度。它保证了重要信息在特定情境下的全面性,即使在内存压缩过程中,算法依然能保持其精确度。这一创新性的成就为算法的深入研究与优化提供了新的方向。

检索头设计:确保信息精准
该算法通过独特的检索策略,有效地保留了文本的核心信息。在处理大量长序列数据时,信息筛选和提取显得尤为重要。检索模块如同精确的探测器,能够精准地识别并提取关键信息。

检索模块确保了功能,即便KV Cache存储空间大幅减少,模型仍能准确提取所需数据。此特性使得算法在实际应用中保持高效和稳定,从而提高了用户的服务体验。

产品集成:提升实际应用

昇腾MindIE/MindStudio产品已整合RazorAttention算法,该算法对8K至1M长序列的KV Cache压缩提供了支持。在32K以上场景的应用中,算法的吞吐量提高了超过20%,这一提升数据直观地展现了算法的实际应用效益。

产品化集成技术让算法快速应用于实际项目,有效降低了企业和开发者的时间和经济成本。算法在多个领域的应用潜力巨大,预计将推动AI大模型技术的持续发展。请问您认为华为的这项算法在哪些行业应用前景广阔?欢迎在评论区分享您的观点,并请别忘了点赞和转发本文!